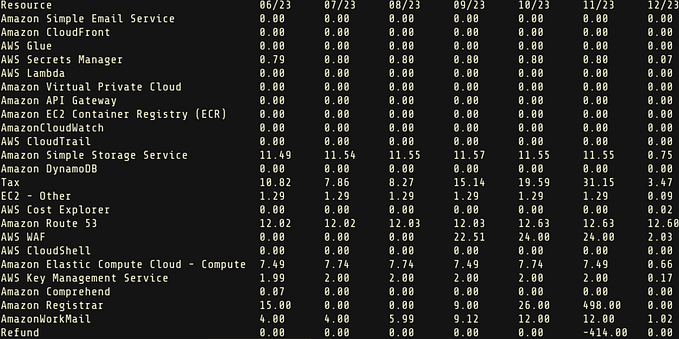
When it comes to managing AWS S3 storage, keeping track of the size of your buckets is crucial for maintaining cost efficiency and operational performance. With some handy scripting, you can easily keep tabs on your data storage. Here, we discuss three different approaches to listing the size of each S3 bucket.
Approach 1: The Simple ls and Recursive Technique
The first approach uses the AWS CLI’s ls command with the --recursive and --summarize flags. This method is straightforward and effective for buckets with a smaller number of objects. However, it can be slow for buckets that contain a large number of files due to the need to list every object.
#!/usr/bin/env bash
set -e
aws s3api list-buckets | jq -r '.Buckets[] | .Name' | \
while read -r bucketName;
do
echo "$bucketName,$(aws s3 ls "s3://$bucketName" --recursive --summarize --human-readable | grep "Total Size" | cut -d: -f2)"
doneApproach 2: Fetching Average Size from CloudWatch Metric Statistics
The second approach taps into the CloudWatch metric statistics to fetch the average size of each bucket over a period. This method provides a quicker overview and is not dependent on the number of objects in the bucket.
#!/usr/bin/env bash
set -e
aws s3api list-buckets | jq -r '.Buckets[] | .Name' | \
while read -r bucketName;
do
size=$(aws cloudwatch get-metric-statistics --namespace AWS/S3 \
--start-time $(date -d '1 month ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date +%Y-%m-%dT%H:%M:%SZ) \
--period 31536000 \
--statistics Average \
--metric-name BucketSizeBytes \
--dimensions Name=BucketName,Value="$bucketName" Name=StorageType,Value=StandardStorage \
--output json)
size_in_bytes=$(jq 'if .Datapoints == [] then 0 else .Datapoints[0].Average end' <<< "$size")
echo -e "$bucketName,$(echo "scale=2; $size_in_bytes / (1024 * 1024 * 1024)" | bc) GB"
doneApproach 3: Enhancing with GNU Parallel
Building on the second method, this approach incorporates GNU parallel to speed up the processing. It’s particularly useful for accounts with a large number of buckets. By paralleling the requests, you can drastically reduce the time taken to get the size of each bucket.
#!/usr/bin/env bash
set -e
function get_average_bucket_size(){
bucketName=$1
size=$(aws cloudwatch get-metric-statistics --namespace AWS/S3 \
--start-time $(date -d '1 month ago' +%Y-%m-%dT%H:%M:%SZ) \
--end-time $(date +%Y-%m-%dT%H:%M:%SZ) \
--period 31536000 \
--statistics Average \
--metric-name BucketSizeBytes \
--dimensions Name=BucketName,Value="$bucketName" Name=StorageType,Value=StandardStorage \
--output json)
size_in_bytes=$(jq 'if .Datapoints == [] then 0 else .Datapoints[0].Average end' <<< "$size")
echo -e "$bucketName,$(echo "scale=2; $size_in_bytes / (1024 * 1024 * 1024)" | bc) GB"
}
export -f get_average_bucket_size
aws s3api list-buckets | jq -r '.Buckets[] | .Name' | sed 's/"//g' | \
parallel --will-cite --jobs 10 --colsep ',' get_average_bucket_sizeExample Output
bucket-name-1, 2.3 GB
bucket-name-2, 754.8 MB
bucket-name-3, 68.5 GB
...Use Cases
- Cost Management: By regularly monitoring bucket sizes, organizations can better predict and manage AWS costs.
- Data Lifecycle: Understanding bucket sizes can help in applying data lifecycle policies more effectively.
- Performance Optimization: Large bucket sizes can affect performance; knowing sizes can be the first step in optimization.
- Compliance: For regulatory compliance, it’s essential to have an overview of the data footprint.
Conclusion
Monitoring the size of your S3 buckets is key to maintaining a cost-effective and efficient cloud storage solution. Whether you prefer a simple command-line request, a CloudWatch metric, or a parallel processing script, you have options to get the insights you need. By using one of these methods, you can easily integrate bucket size monitoring into your regular AWS maintenance routine, ensuring you stay on top of your storage needs.